6/15に今年2月から3月に連続して起きたみずほのシステム障害調査報告書が発表されました。部外者からすると結構読み物として面白く、また示唆に富んでいるので感想を書きます。
自分がアプリエンジニアなのでその方面の観点が多め。
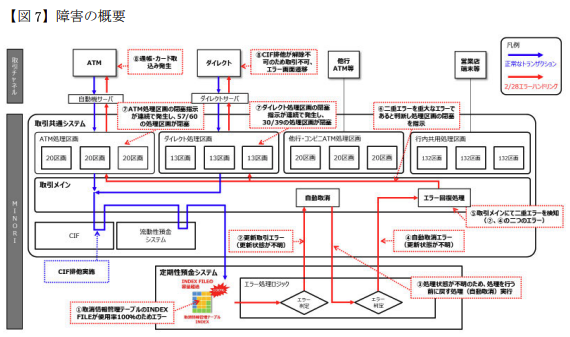
あらすじ(P.36)
2/28 9:50に大量データ登録によって定期性預金システムにおける取消情報管理テーブルがDiskFull(実際はオンメモリのINDEX格納領域の不足)になって全死
→ 取消情報管理テーブルが全死なので、定期性預金トランザクションの取消そのものができなくなる(2重エラー)
→ この2重エラー状況を検知した上位システムにより防御機構が作動し、ATMやダイレクトチャネルの流量制限が行われる
→ 流量制限されたATMでカード飲込みが発生
おもしろポイント1:初動の暫定対応を完全にミスっている
システムには2種類の防御機構があったようである。
1つ目は、1系統で同じサービスが30回エラーになったら、そのサービスそのものが使用できなくなるようにメニューから自動で消す「取引サービス禁止機能」(P.51)。今回だと、定期性預金サービスが全死なので、ATMのメニューから定期預金関連のメニューが消えていった。なんかちゃんと動いてないサービスあるからそれ使えないようにしといたろ、的なヤツ。
2つ目は、2重エラー(≒パーコレートエラー)が5回発生したときに、そのきっかけとなった処理区画を自動で閉じる機能(P.46) 。なんかシステム全体ヤバそうだから入り口を閉めて全体に負荷かからないようにしたろ、的なヤツ。
なお、システム全体は3系統あり、1系統ごとにATM処理用に20区画が用意されているとのこと。多分1区画ごとに複数個のトランザクションを走らせることができると思われる。「系統」は全く同じシステム構成が3個ある(負荷分散と可用性確保用)と思われる。そのへん詳しく書いてなかったのでわからんが。
で、今回は前述のように定期性預金サービスが全死だったので、もしなにかするなら、前者の防御機構を強めてなるべく皆が定期預金系サービスを使えないようにする必要があった。
が、あろうことかこの制限を30回→999回に緩めてしまった。この結果、皆が(抑制されていた)定期預金系サービスをつかえるようになって、それが全部エラーになって、後者の防御機構発動→ATMの停止祭り、となってしまった。
障害の真っ只中で混乱はあったのだろうが、それを差し引いても無能な対応だったと言わざるを得ない。なお、作業の指示と実行は11:37-12:08の期間で行われているが、11:30の時点で(定期性預金サービス内の)DBのDiskFullという根本事象が常務に報告されているので、この時点で常務に整然と報告できるほどに根幹は見えていたと思われる(P.38)。
なのになぜw この失敗が致命的である旨が報告書で数パターンのグラフwで示されており(P.41,53)、そのあと結局定期性預金サービスは完全に切り離したので、この措置矛盾しすぎだとか、昔うまく行った記憶をもとにノリでやりました的なこともバラされていて(P.76)もはやフルボッコ状態ww この指示者の行く末が気になるところである。
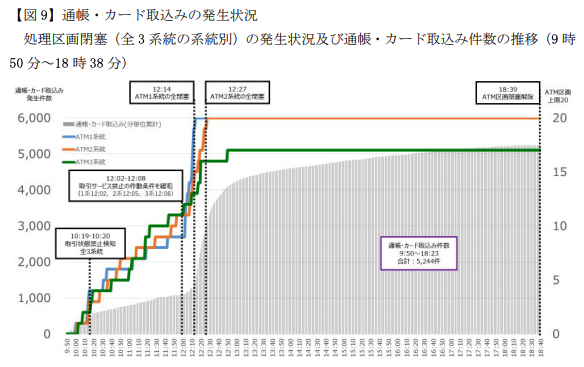
おもしろポイント2:根本事象解決後、ATMが回復しなくて大混乱
本件、先に述べたとおり根本事象はDBのDisk(オンメモリ格納領域)Fullである。領域拡張が終わったのが14:54、これを利用する定期性預金性サービスを16:22に再開完了している(←起動に1時間半もかかるのな)。
どうもここで一旦障害対応が終わったと思ってたフシがある。16:37から障害の過程でロックされた顧客ファイルの解除を試みており、つまり事後処理を始めてることが見て取れる。
一方、ようやく防御機構2によってATM処理区画が閉塞がされてたことを認知したのは17:10である。この間、だいぶ混乱したんだろうなあと。「ダメです!ATM回復しません!」「そんなバカな」みたいな。エヴァかな?ぜひ再現ドラマを作って欲しい。
こういう安堵からの再混乱みたいな話好きなんですよね。完全に他人事だから言えますが。
思うに、対応担当者は防御機構2(パーコレートエラー検知によるATM閉塞)を知らなかったのではないかな?定期性預金でのエラー→ATMの閉塞と直接的に考えたのではないだろうか。なので、定期性預金のエラーが検知されないようにするために、おもしろポイント1の対応を行ったのではないかと。
まあ実際にはエラーが検知されないようにする対応ですらなかったわけで、やっぱり草生える対応なわけですがw
原因と"現実的な"再発防止対応を
報告書にはさまざまな側面における原因が記載されている。
原因DiskFullだったわけなので、当然「DiskFullになる可能性を予期してレビューや事前確認を行うべきだった」てのは出ると思うんです。が、これ現実的じゃないと思うんですよね。インポート対象のテーブルがDiskFullになったのならともかく、「定期性預金サービスの、共通処理を担う取消情報テーブルの、INDEX領域がオンメモリに格納されかつそれが当日の処理量に応じて増加する性質に基づき、さらにメモリ利用量の監視警告が見逃される可能性」を予期できるか?という。
ひとはいつでも間違いを犯す、という観点に立つとあらゆる内容をルール化するとか運用体制をガチガチにしばるのもあまりイケてないなあと思います。間違いを犯しても大丈夫な仕組みを構築することが大事と思うのです。
なのでその観点でこれはできたやろという"現実的"な対策を2つ上げたいと思う。
1.カード飲み込み条件の変更
ま、これよね。P.69の原因(オ)として記載がある。前述の通り防御機構は2種類あって、定期サービスやばいから定期サービス止めとこ、と、なんかわからんがやばいから全部止めとこ、の2つ。
その内訳が↓(P.47)
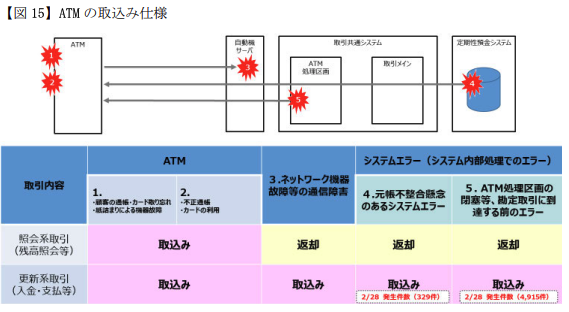
要は、「なんかやばいから全部止めとこ」の方で引っかかって飲み込まれた人が4915件と大多数。
この後者のほうがカード戻す仕様であれば、障害数が5244→329件に抑えられた上に、「定期預金サービスでエラーが発生したので、定期預金サービスを使おうとしたお客様の資産保護のためにカードをお預かりしました」と一応辻褄がある説明ができたはずなのだ。
最もあかんのは、過去3回も同様のトラブルを起こしていた(P.69)のになにもしてなかったこと。この大障害の発生後に速攻直した(P.133)らしいけど、なんだ速攻直せるんだな、最初からやっとけやそういうとこやぞと思わなくもない
人間だから、悪い仕様に気づけないことは多々あるだろう。でも同じトラブル3回も起こしたら、さすがになんかおかしいと気づけよ、と思う。
2. フェイルセーフ機能のテスト不足
P.67(イ)として記載あり。
原因は定期性預金サービスの取消情報テーブルがDiskFullになったことである。明確に記載がないが、おそらくなにか処理を実行する前、最初に実行前情報をコピーしておく(そして戻せるようにする)情報テーブル/機能だと思われる。(DBのロールバックが効かなかったときの保険的機能である旨の記載がある)
それで、この最初の処理が死んでたので事実上なにもできない状態だったと。処理エラー時に整合性が失われたか否かを返す機能があり、それを元に取消を行うか否かを判断しているのだが、それがバグってて常に取消処理を要求するようになってたとのこと。そしてその取消処理もコケるので2重エラー≒パーコレートエラーとなって、ATM閉塞を招いたと。
ここも、うまく動いていれば、障害数が329件で定期預金サービスを使おうとしたお客様のみへの影響で抑えられたはずなのだ。
取消情報テーブルの名のごとく、これはシステムがなんかやらかしちゃったときの最後の防御機能なので、特に重点的にテストすべきだったし、SPOFとなりえる点も踏まえるとオンメモリINDEX保持への設計変更も慎重にすべきだったように思う。
ここが原因だったから云々じゃなくフェールセーフ機構だからという観点が大事。
人間はいつでも間違える、だからフェールセーフがある。そのフェールセーフがさらに間違えないように狙いを絞って慎重にレビューとテストをすべきだった、と思う。
---
人はいつでも間違える。締め付けて管理すれば何でもできるわけではない。未来をすべて予測できるわけでもない。だから、間違いに気づいたら改善しよう。間違いが起こっても大丈夫なような仕組みだけはしっかり作ってみんなで保証しよう。
この辺がうまくできてなかったんだろうなあと思うし、これがうまく回るような"現実的"でシンプルなルールができれば良いと思う。間違ってもチェックリストが何十枚にもなるとかそういう無理ゲーな対応になりませんように。
ネット上の指摘への対応
みずほの話になるとなぜかネット上で知ったかして適当なこという人が増えるのでそこへのコメントを。
20万人月のあのシステムがまだ未完成なんだろ/バグだらけなんだろetc
あらすじ部分にも書いたように、特定サービスのDB DiskFullが原因であり20万人月システムことMINORIのバグではない。
報告書要旨版の原因欄の一番上にも「MINORIの構造、仕組み自体に欠陥があったのではなく、これを運用する人為的側面に障害発生の要因があった」とはっきり書かれている。
2週間で4回も障害を発生させるとか無能の極みすぎる
実は最初の1回以外、残り3回のうち2回はハードウェア故障を検知して自動切り替えしたという事象で、どちらかというとうまく動いた事象である。
残り一回は初歩的なプログラムミスだが、まあ正直よくある話で、全部一緒にして4連続障害として叩かれたのはかわいそうに思う。
藤原頭取の責任問題
めちゃくちゃある。
リーダーシップのリの時もみえない。公式な緊急対応体制が構築されたのが事象発生から7時間以上経ったあとという1点のみで辞任はやむなしである。全く危機管理体制が機能していない。就任から3年以上こんな感じだったのに、再発防止策の徹底のために続投とか片腹痛い。この報告書書いた人に頭取になってもらえ
当日の対応内容(誰も個人として組織横断的アクションを取らない)がありえない
まあ、わかるよ。言いたいことは。
でも有事に断片情報を元に本当に正しい行動を取れるだろうかと。顧客に情報を伝えるにしても、それが間違っていた場合どうすれば、などまで考えるとなかなか動き出すのはつらそうなのもわかる。
個人的にはこれ系のアプローチよりも問題そのものが起こらなくできたり局所化できたりできるように仕組み作ってくべきなんだろうなと思う。
DBがバラバラで運用が大変そう
みずほ銀行のシステム障害、データベースの運用ミスが障害の発端だったんですが、これだけDBがバラバラだと、そりゃあ運用も大変かと。詳細は記事をご覧下さい https://t.co/WRUEd5JN54 pic.twitter.com/GE984QR1F0
— Atsushi Nakada (@Nakada_itpro) 2021年6月15日
たしかにDBがバラバラで運用が大変そうだが、今回の直接の事象とDBの多様性は関係ないように見える。
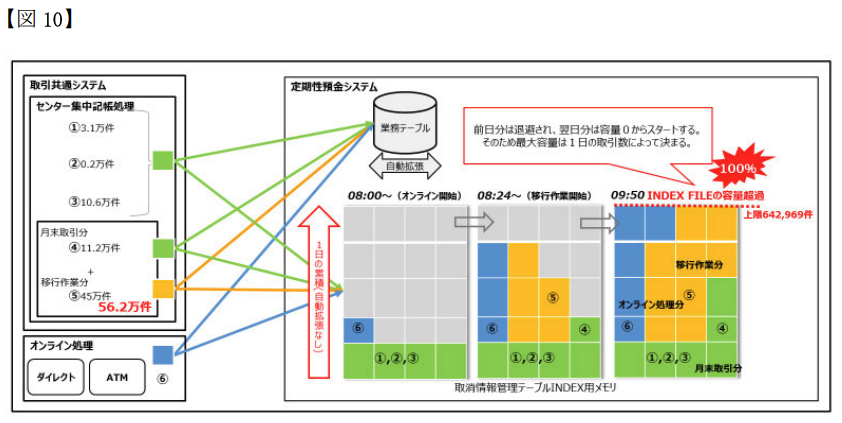
が、そもそもの根本事象である取消情報管理テーブルのINDEX FILE容量超過。報告書内に何度も書かれているように、テーブル本体ではなくてINDEXだけがメモリ上に常駐しているらしい。そして、前日分のINDEX容量は退避されて、当日の処理量に応じてINDEX容量が増えるらしい。これって普通のDBMSでできる話なんですかね?いまいち直感に反する話なのですが、前日分までが退避領域(HDD,SSDなど)にあって当日分だけがメモリにあって、それらが透過に扱えるってこと?そういうの、今は普通なの?
そもそも取消情報管理テーブルの名前からして一時テーブル(グローバルトランザクションの生存期間でのみ有用な一時データ)みたいなイメージですが、それが日をまたぐ事があるってこと?いまいちよくわからない。このへんの「わからなさ」がDBMS固有の機能だったり固有の設計制限であったりするなら、多様なDBMSを運用している副作用かもしれない、とは思いました。
その他
パーコレートエラーってなに?
どうみても専門用語(IBM用語?)なのになんの解説もない。最初は2重エラーのことかと思ったけど、2重エラーのようなシステム全体の非安定稼働を想起させるような重大なエラー/イベントのことっぽい